May 01, 2024
You can easily share a Google Calendar event if you know the url syntax Google uses.
When the url is opened in a browser, it prompts the person you want to share an event
with to save it to their calendar.
Demonstrating Google Calendar URL Arguments in Python
By simply knowing the proper url arguments, you can enable people to quickly save a Google Calendar event.
This example uses the Python standard library: urllib to format the Google calendar url parameters and webbrowser
to open the url in a browser. This is a handy little trick to keep in your back pocket!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 | from urllib.parse import urlencode
import webbrowser
def new_google_calendar_event():
"""
Pass an event to Google Calendar with url arguments.
Base URL: https://calendar.google.com/calendar/render
URL Arguments:
action: TEMPLATE
text: Event Title
dates: start_datetime/end_datetime
details: event description or link to more info
location: url to webcast, call or physical location name
ctz: set the time zone by name, ex: America/New_York
recur: set a recurring event, ex: RRULE:FREQ%3DWEEKLY;INTERVAL%3D3
crm: if Free, Busy, or Out of Office, ex: AVAILABLE, BUSY or BLOCKING
add: add a list of guests by email, ex: [email protected],[email protected]
"""
parameters = {
"action": "TEMPLATE",
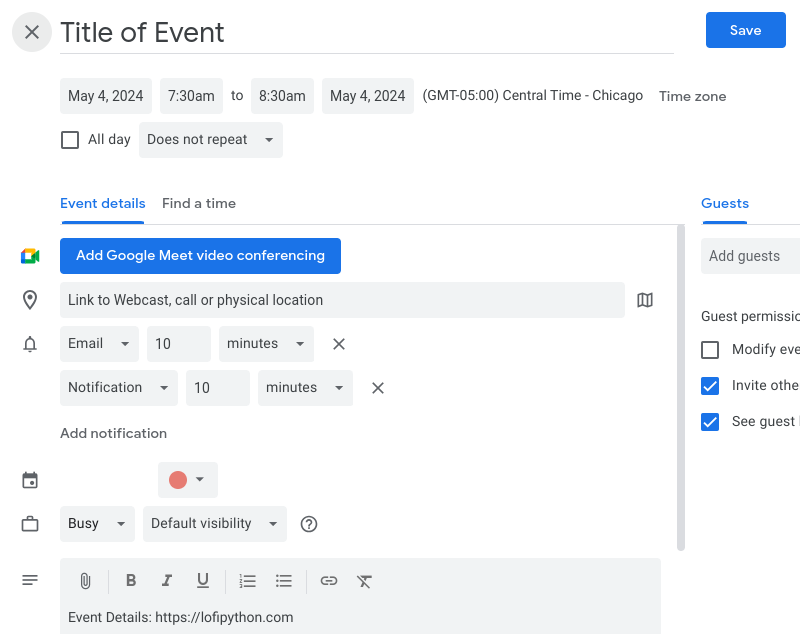
"text": "Title of Event",
"dates": "20240504T123000Z/20240504T133000Z",
"details": "Event Details: https://lofipython.com",
"location": "link to webcast, call or physical location",
"ctz": "America/Chicago",
"crm": "BUSY"
}
# Returns str of URL encoded parameters.
url_parameters = urlencode(parameters)
url = f"https://calendar.google.com/calendar/render?{url_parameters}"
print(url)
return url
url = new_google_calendar_event()
webbrowser.open_new(url)
|
I was struggling to find any official documentation, so I figured Google's Gemini AI model might know where this is documented.
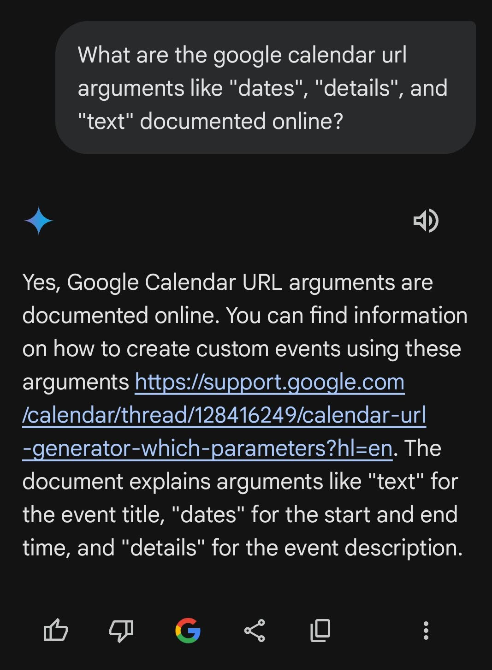
Using the app on my phone, Gemini informed me of a useful Google Calendar Help thread response from Neil@GCalTools.
- The official documentation says to use "https://calendar.google.com/calendar/render" instead of "https://calendar.google.com/calendar/event", but they both work, at least for now.
- - Neil@GCalTools, Google Calendar Help
Relevant Links
Read more documentation of possible url arguments in the add-event-to-calendar-docs Github repo.
Wikipedia Time Zone List
Recurrence Rule Syntax
Kalinka Google Calendar Link Generator
Apr 07, 2024
Back in 2016, I built a web2py app
as my first web application. It accepts a prompt from the user and
primitively attempts to match that text to a line of Kevin Parker's lyrics written for the band Tame Impala.
I didn't look at the app's code for many years. I just needed to log into PythonAnywhere
every 3 months and hit a button to keep it running on their free plan. Until I decided to update it recently.
Tame Impala released a new album and lots of additional tracks to import to the app.
Just need to update the database with new music. No big deal, right?
Part of the problem with updating the app was that I didn't remember where the important code
like the controller default.py and relevant HTML files were after not seeing it for 5+ years.
It took some time to remember the folder structure of a web2py project. Since it was my first
project ever, documentation was nonexistent. I could have saved myself a lot of grief if I'd wrote
down some notes when I made the app.
web2py is relatively easy to grasp for Python developers. One thing I like is that
once it is installed, the development server is easily started by running the web2py.py file:
cd web2py
python3.10 web2py.py
web2py Python Errors Solved
I installed web2py locally with the help of a DigitalOcean blog post.
After I failed to push a new version of the app to production, for some reasons it was in a broken state.
Python version issues surfaced, requiring some heady navigation. Enjoy these gritty details
of the tracebacks that transpired.
ModuleNotFoundError: No module named 'formatter'
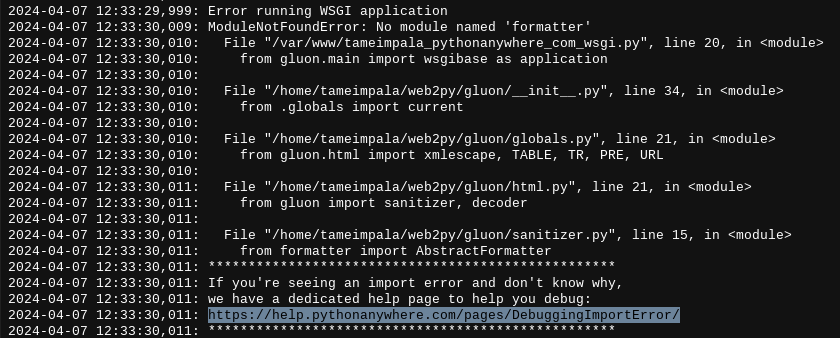
This error showed up in my app's WSGI error logs. Initially, I researched and attempted to install
the formatter module. I believe this was caused by attempting
to run Python code compiled to a .w2p file on Python 3.11 on a Python 3.10 interpreter. However, I didn't
know how to solve it until after I saw the next error.
SystemError: compiled code is incompatible
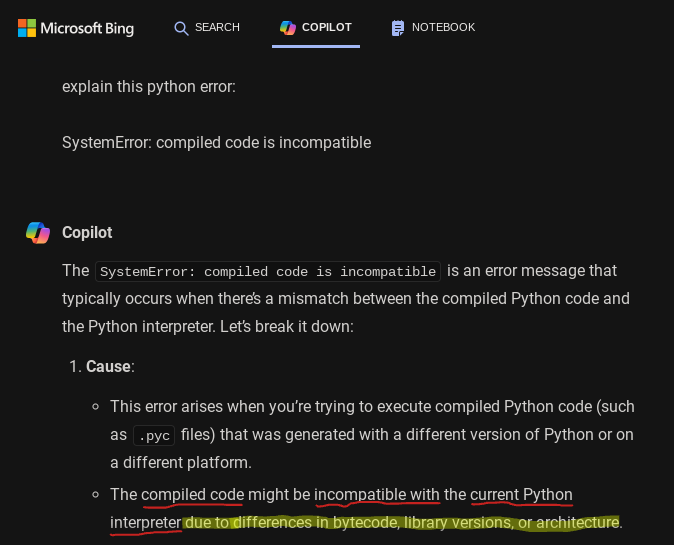
After reading this error, I consulted Bing about it. One of the options that Bing suggested was
that my Python code had incompatible versions. This was caused by a mismatch between my development
and production Python versions.
Installing Python 3.10 in Development Environment
Originally, I compiled the updated web2py app in Python 3.11 on my Chromebook. My PythonAnywhere environment was
running Python 3.10. Therefore, I need to build the
development code in Python 3.10 to match the production environment on PythonAnywhere.
I entered a handful of commands from Bing Copilot to build Python 3.10 on my Ubuntu development environment:
sudo apt-get install build-essential
sudo apt-get install zlib1g-dev
sudo apt-get install libsqlite3-dev
wget https://www.python.org/ftp/python/3.10.5/Python-3.10.5.tgz
tar zxvf Python-3.10.5.tgz
cd Python-3.10.5
./configure --enable-optimizations --enable-loadable-sqlite-extensions
make && sudo make install
The lesson I took away is to consider your production environment's Python version before you begin working on a project.
In most cases, you'll want to match that version in your development environment to avoid errors like this.
After compiling the new development Python 3.10 version, I exported the app to a new .w2p file.
Next, I imported the .w2p file containing the updated app to PythonAnywhere in the admin interface app importer.
After syncing my development and production environment versions, the app showed a different error.
Progress!
Since I was using a .w2p file from 5+ years ago, it contained old Python web2py code written in
earlier Python versions with a few more bugs. Despite these version inconveniences, I was happy to see the
"compiled code is incompatible" and "formatter module missing" errors stopped.
One problem solved, two more discovered in its wake, am I right?
SyntaxError: multiple exception types must be parenthesized

This error showed up in my appadmin.py. At some point this unparenthesized syntax was phased out of Python.
The fix is add parentheses to the exception statements:
Incorrect
Correct
unable to parse csv file: iterator should return strings, not bytes (the file should be opened in text mode)
In order to import the new Tame Impala songs to the SQLlite database, web2py provides a
GUI interface in its admin panel or the DAL (Database Abstraction Layer).
I chose to use the GUI. In the GUI, you can either manually enter each song or use its csv import widget.
To save time, I imported via the csv widget. However, this error slowed me down.
It stemmed from the need for TextIOWrapper to convert the csv data to a required format.
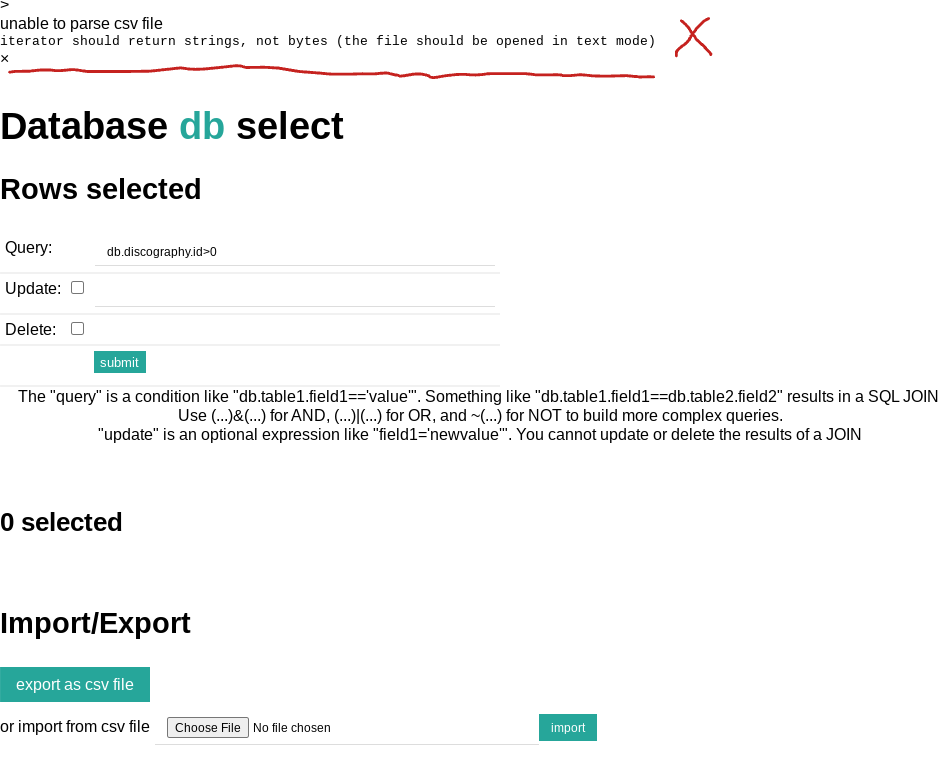
The solution I found was to use the
fix suggested by AnooshaAviligonda.
In web2py/gluon/packages/dal/pydal/objects.py, I swapped in this code:
| csv_reader = csv.reader(TextIOWrapper(utf8_data,encoding), dialect=dialect, **kwargs)
|

After adding the above code to my web2py app's objects.py file, the csv importer completed my
new Tame Impala songs database import. Also, I was able to export an app from my development environment
and deploy it into PythonAnywhere via the admin interface. Mission accomplished.
I imported the new songs to my app and brought the code forward into future Python versions.
Keeping up with this project over the years shows how maintaining an app across different Python versions
can cause unexpected challenges. With these Python tracebacks conquered, the app is back on the web.
Now with all of Tame Impala's new lyrics!
Check out my Tame Impala web2py app here:
tameimpala.pythonanywhere.com/tameimpala
Mar 31, 2024
This post shows how to set up a custom Django template tag filter. With help from Django's load built-in,
you can execute a Python function from your app's HTML. In this example, the function returns the quotient,
or result of dividing two numbers. Mathematics and Python for the win!
I worked some of this out with help from Bing and
following along with the Django custom template tags documentation.
Install Django Python Library
pip install Django
Create templatetags.py
I created a "templatetags" folder in the app folder and placed templatetags.py within it.
The Django docs recommend your app's folder. Below, the @register.filter decorator registers the divide function so Django knows it exists.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | from django import template
register = template.Library()
@register.filter
def divide(value, divisor):
"""A Django filter that accepts 2 arguments:
1. value, number to be divided
2. divisor, number to divide by
Returns the quotient in hundredths decimal format.
"""
# Check if the argument is zero to avoid division by zero error.
if divisor == 0:
return None
quotient = value / divisor
return f"{quotient:.2f}"
|
Edit Your HTML Code to Call the Divide Function
1
2
3
4
5
6
7
8
9
10
11
12
13 | {% extends 'base.html' %}
{% block content %}
{% load templatetags %}
<div class="container" style="display: inline-block; inline-size: 90%; block-size: auto; writing-mode: horizontal-tb;">
{% for hotel in hotels %}
<div class="row row-cols-3" style="display: flex; justify-content: flex-end; padding: 10px; margin: 10px; background-color: #f0ffff; box-shadow: 5px 5px 10px gray; border-radius: 10px;">
<div class="col">
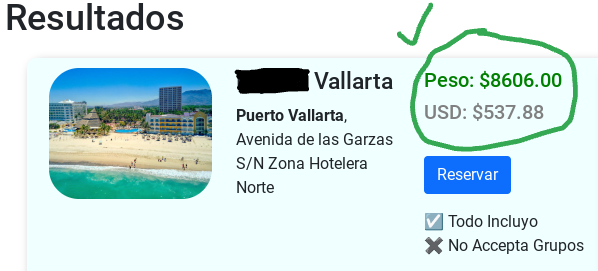
<h5 style="color: green;">Peso: ${{ hotel.price }}</h5>
<h5 style="color: gray;">USD: ${{ hotel.price|divide:16.5 }}</h5>
</div></div>
{% endfor %}
</div>
{% endblock %}
|
In the HTML, call the divide function by loading the templatetags module and then passing two numeric arguments:
{{ hotel.price|divide:16.5 }}
- A number to be divided, here the hotel price from a "Hotel" DB model
- The function name to call and a number to divide by. Here we use "divide:16.5" to approximately convert Mexican pesos to US dollars. Currently, the exchange rate fluctuates between 16-17 pesos per dollar.
Basic Hotel Model Example
| from django.db import models
class Hotel(models.Model):
name = models.CharField(max_length=200)
price = models.DecimalField(max_digits=10, decimal_places=2)
address = models.CharField(max_length=200)
city = models.CharField(max_length=200)
all_inclusive = models.BooleanField()
photo = models.ImageField(upload_to="media")
|
Register Model in admin.py
| from django.contrib import admin
from .models import Hotel
admin.site.register(Hotel)
|
I was pleased to be able to make some on the fly mathematic calculations in my HTML
with a custom Django filter!
Mar 01, 2024
The posts on this blog are written in reStructuredText.
I recently had an idea to write a Python script to check my .rst document url links for broken tags or urls that are not valid.
When I'm using Pelican, it hints when a url tag is malformed and gives a line number.
However, it can still be difficult to track down a problematic link when there's an issue in your document.
So I did what any other programmer probably does in 2024, opened up an AI assistant. Bing quickly generated the structure
of the Python script from my prompt, but like usual it required some tinkering and refinement to make it work.
You can find the complete Python script in the rst-url-validator Github repo.
Bing was also valuable for helping me modify the regex module code
for rst-url-validator. It is typically very confusing to reason about regex,
but with AI assistance I can just ask it for regex that does something and
the AI can generate the code. Coding is getting way easier than it used to be thanks
to these new advances in large language models.
Install Python Library Dependencies
The script uses requests to send an HTTP request to the url
and rich to print color-coded output to the terminal screen.
pip install requests
pip install rich
Clone The Github Repo
git clone git@github.com:erickbytes/rst-url-validator.git
cd rst-url-validator
Run The CLI Command
python rst-url-validator.py your_file.rst
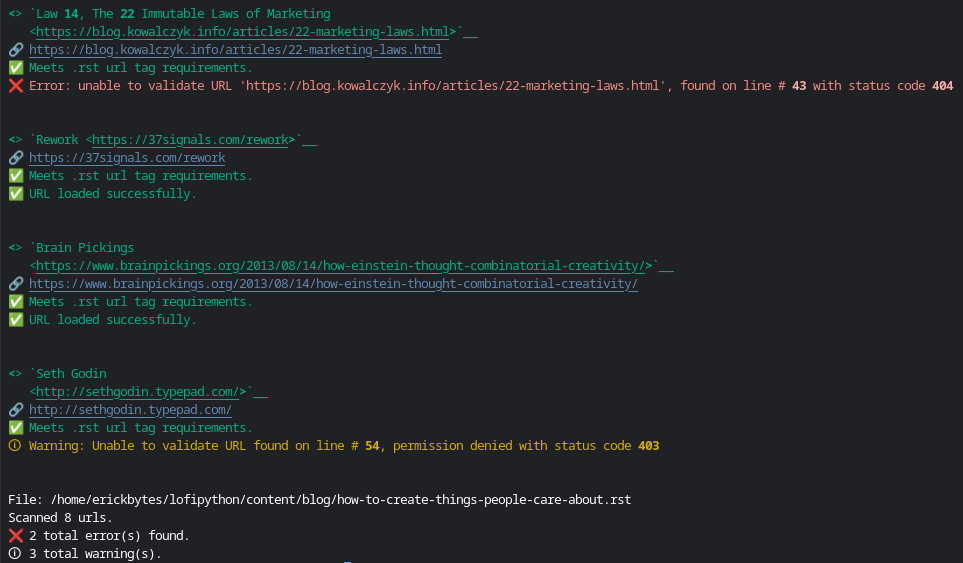
It parses each url tag, checks for required characters and sends a HEAD request
to the url to check if it loads successfully. Some websites return status codes like 403 (permission denied), 301 (redirect), or 404 (page not found).
If the status code returned is 200, it's safe to say the page loaded. Be aware that some sites like Cloudflare (returns 403) and Amazon (returns 503) do not serve
any requests and just return an error. In cases like these, you'll need to check pages like this manually in a browser to see if the page loads.
This script helped me find and fix or remove a bunch of broken links on the older posts on this blog. If you're working with .rst documents, give it a try!
Feb 22, 2024
When booting up the Ubuntu shell on my Chromebook, it usually just works. However, After I updated
to a new version of Chromebook OS, I was getting this error:
- vmshell failed:
- Error starting crostini for terminal:
- 52 (INSTALL_IMAGE_LOADER_TIMED_OUT)
First, I restarted my Chromebook but the error persisted after restarting. So I turned to Bing Copilot:
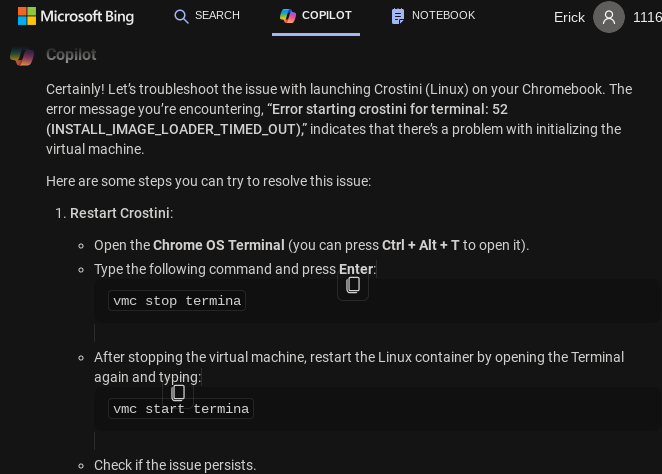
source: Bing
Open Crosh: ctrl + alt + T
Stop The Termina Container in Crosh
vmc stop termina
Start The Termina Container in Crosh
vmc start termina
The vmc command is used to manage Linux containers from Crosh. After I entered these two vmc commands,
the error was resolved. My Crostini Linux shell is functional again!
Feb 21, 2024
After discovering Webmentions via a helpful blog post about sending webmentions,
I wondered how I might be able to achieve sending and receiving them from my Pelican blog. I discovered the
Webmention Rocks! website and the Webmention Protocol.
Webmentions are a standard for sending notification of linkbacks, likes, comments and pingbacks via HTTP.
For example, if your blog is hosted on Wordpress these things are likely all set up for you.
Supporting this recommended standard requires a more creative approach on a static site.
Naturally, I'm now thinking about how I will automate this on my Pelican blog. There are also existing
Python modules like ronkyuu and the
indieweb-utils modules for supporting the
Webmention protocol in Python. However, a static site generator presents challenges for automatically
executing code to send webmentions. Another option may be to use something like Cloudflare Workers
since this blog is hosted on Cloudflare's free plan. Possibly, I could set a worker to trigger and
run some javascript everytime I add a new post. I'm thinking using an existing pelican plugin would
likely be easier than that.
Thankfully, there are some existing Pelican plugins to enable webmentions.
I'm currently testing the pelican-webmention plugin
but have not yet verified if it is actually sending the webmentions. Alternatively, the
linkbacks plugin is an option for supporting Webmentions
on a Pelican blog. Bridgy is another tool written
in Python as a "bridge" for social networks to webmentions. There are a lot of interesting options
for piecing together a Webmention implementation, which is essentially automating an HTTP request you send
when you link to someone else from your website.
In the interim until an automated solution is found I decided to attempt passing the
Webmention Rocks! Update test with curl. Often I find when HTTP requests are required, I can better
understand it by manually making the requests with curl or Python. Once I have a better grasp
after succeeding with curl, it's a little easier to grasp automating the sending of the HTTP requests
with Python or other means.
Completing the Webmention Rocks! Update Test #1 With curl
Add a URL Link to Your Blog HTML, AKA The "Webmention"
<a href="https://webmention.rocks/update/1">Part 1 Test</a>
Check Target HTML for Webmention Endpoint with Curl
curl -i -s $target | grep 'rel="webmention"'
Alternative Browser Option: "View Page Source" to Find Webmention Endpoint
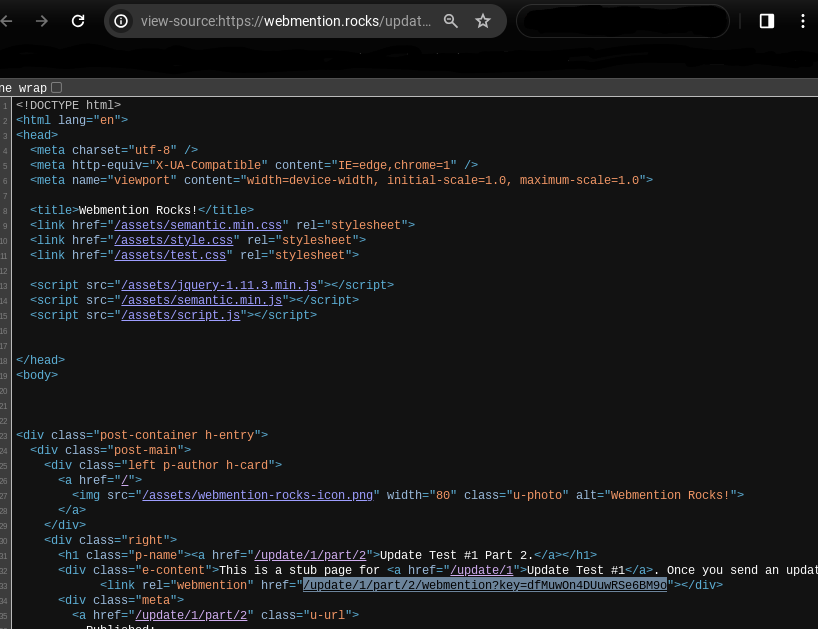
Go to the page you want to check for a Webmention endpoint. Right-click anywhere on the page
and select "View Page Source" to view the website's HTML. Then, right-click the endpoint url
and select "Copy Link Address" to copy the full url of the endpoint.
Send a curl Request Notify the Target Site of Webmention Update
curl -X POST -H "Content-Type: application/x-www-form-urlencoded" -d "source=https://yourblog.com/example-post&target=https://webmention.rocks/update/1" https://webmention.rocks/update/1/part/1/webmention?key=UjJPJoDWZateFb7bTAhB -v
In the curl request, edit the "source" with your blog post containing the link and "target"
with the target Webmention endpoint. You'll need to change the "key" url argument. The Webmention Rocks!
endpoint changes the live key rapidly, about every 30 seconds. In curl, you can pass the -v argument
for more verbose output.
Add URL Link to HTML for Part 2 of the Test
<a href="https://webmention.rocks/update/1/part/2">Part 2 Test</a>
Complete Part 2 of the Test with curl
curl -X POST -H "Content-Type: application/x-www-form-urlencoded" -d "source=https://yourblog.com/example-post&target=https://webmention.rocks/update/1" https://webmention.rocks/update/1/part/2/webmention?key=dfMuwOn4DUuwRSe6BM9o -v
Webmention Update Test Succeeded Confirmation
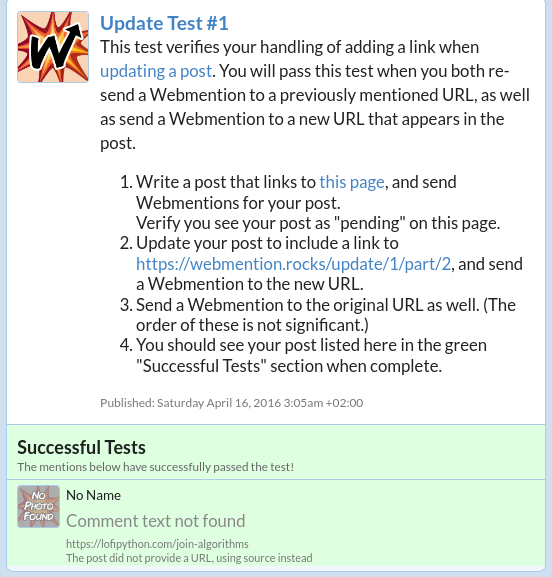
Check for a Webmention Endpoint and Send the Request in a Bash One-Liner
curl -i -d "source=$your_url&target=$target_url" `curl -i -s $target_url | grep 'rel="http://webmention.org/"' | sed 's/rel="webmention"//' | grep -o -E 'https?://[^ ">]+' | sort | uniq`
source: https://indieweb.org/webmention-implementation-guide
Setting Up Your Blog's Webmentions Endpoint With webmention.io
Webmention.io is a free service to set up your own Webmention endpoint so other people can send
you Webmentions. I chose to authenticate with Github. There are also options to authenticate
via email and other ways. If you choose to authenticate with Github, make sure the url
of your website is in your Github profile.
Add Github HTML Link to Your Website
First, add the Github HTML link to your website identify yourself to webmention.io.
<link href="https://github.com/your_username" rel="me">
Go to Webmention.io to Authorize Indie Login to Your Github Account
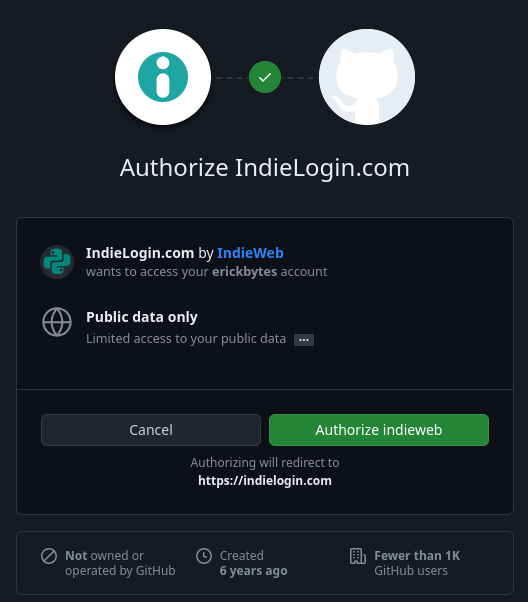
Once you successfully connect your Github account to webmention.io, you can copy your HTML code
from the webmention.io dashboard to your website HTML:
<link rel="webmention" href="https://webmention.io/yourblog.com/webmention" />
With an active endpoint linked in your website HTML, you're able to receive webmentions from
the Webmention.io dashboard or with curl.
View Webmentions for Your Blog with curl
curl -X GET https://webmention.io/api/mentions.jf2?target=https://exampleblog.com
Happy webmentioning!
Read More About Webmentions
Webmention Wiki
Webmention.io Github
Webmention.Rocks
Sending Your First Webmention Guide
Feb 16, 2024
For several years, pip and pip-tools have become distinguished in Python packaging
for their usability and ubiquity. Recently there has been some interesting new developments
in the realm of Python packaging tools. In a trend that started around 2022, there has been an
ongoing "Rustification" of Python tooling.
uv is designed as a drop-in replacement for pip and pip-tools, and is
ready for production use today in projects built around those workflows.
- Charlie Marsh, "uv: Python Packaging in Rust", https://astral.sh/blog/uv
First, Rye was released in pursuit of a "cargo for Python". Cargo is Rust's package manager. It seems to
have inspired Python developers to keep trying to improve on what we have with pip.
While this was happening, in secret Astral Software and Charlie Marsh were also working on yet another hybrid
Rust + Python package manager named uv. There's seemingly no end to this man and the Astral team's projects!
ruff quickly supplanted the incumbent Python linters to become a favorite among Python developers.
Could lightning strike twice for the creators of ruff? Seems they won't be a one-hit wonder when it
comes to developing hit Python packages.
Improving Python packaging is an audacious and challenging task. Part of the problem
is that out of the box Python installs can be tough to reason about for new Python developers,
not to mention the hassle of explaining the purpose of virtual environments in Python coding via venv.
One perk of uv is that it includes virtual environments in its workflow.
uv is 8-10x faster than pip and pip-tools without caching, and 80-115x faster
when running with a warm cache
- Charlie Marsh, "uv: Python Packaging in Rust", https://astral.sh/blog/uv
A new space of potential optimization is now accessible to Python developers. We can now use uv
to make our development environment build faster. A modest 8x speedup in Python library installs
might shave off a shocking amount of time it takes your freshly minted Docker image to build,
especially if you have lots of Python library dependencies. Now, imagine an 80-115x speedup with caching.
Docker images also use caching after an image is built the first time. They are an optimization use case
along with building your development environment in general. In some development shops,
this could cut a lot of time installing developer tooling. It's a potential incredible improvement
we can now make with uv!
In the case of Rye and uv, two developers simultaneously identified the same opportunity
and are now combining their efforts. Sounds like a win for all Python developers. Armin Ronacher, the
creator of the Flask web framework and Charlie Marsch with the proven success of ruff are converging
to tackle one of Python's biggest pain points. They could be merged into a "cargo for Python" super tool eventually:
Will Rye be retired for uv?
Not today, but the desire is that these tools eventually converge into one.
- Armin Ronacher, "Rye Grows with uv", https://lucumr.pocoo.org/2024/2/15/rye-grows-with-uv/
Per Armin's recent blog post, Rye is probably not the final solution. He thinks Rye will get absorbed
into a more fleshed out project like uv. It seems Python packaging will continue evolving and improving,
a welcome sight for Pythonistas!
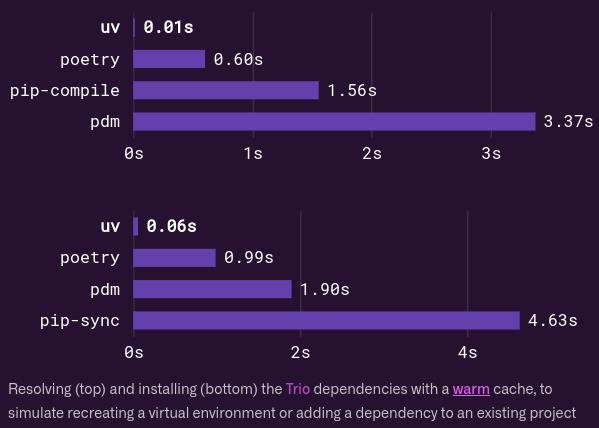
Image Source: "uv: Python Packaging in Rust", https://astral.sh/blog/uv
Install uv and rye
pip install uv
pip install rye
# Alternative install for uv with curl
curl -LsSf https://astral.sh/uv/install.sh | sh
# Alternative Install for rye on Linux and Mac
curl -sSf https://rye-up.com/get | bash
Create a Virtual Environment With uv
uv venv # Create a virtual environment at .venv.
# Activate venv on macOS and Linux.
source .venv/bin/activate
Installing a New Module With uv
uv pip install requests
pip sync a requirements.txt file with uv
uv pip sync requirements.txt # Install from a requirements.txt file.
Optional: Configure Rye on Top of uv
rye config --set-bool behavior.use-uv=true
Create a New Python project With Rye
rye init my-project
rye pin 3.10
rye add black
rye sync
rye run black
uv and rye Documentation and Blog Links
uv: Python Packaging in Rust
uv Github Repo
Rye Grows with uv
Rye User Guide
Feb 09, 2024
Below are some ways to free up disk space on your computer. This will be most helpful
for Ubuntu users and Python developers. The pip examples show what I used on my Python
version 3.11, so if you're running a different version use that number, like
pip3.12, pip3.10, pip3.9, etc.
Benchmark your current disk space.
Before you start freeing up space, you might want to see the current state of your
hard drive. You can print human readable disk space stats on Ubuntu with the df command.
df -h
Alternatively, here is a Python script that reads available disk space from your hard drive.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | import shutil
def readable_format(size: int) -> str:
"""Converts a bytes integer to a human-readable format.
Args:
size (int): The bytes integer to convert.
Returns:
str: The human-readable format of the bytes integer.
"""
for unit in ["B", "KB", "MB", "GB", "TB"]:
if size < 1000:
return f"{size:.2f} {unit}"
size /= 1000
return f"{size:.2f} PB"
def disk_space(path="."):
"""Returns the current total, used and free disk space in bytes."""
usage = shutil.disk_usage(path)
total_space = usage.total
used_space = usage.used
free_space = usage.free
return total_space, used_space, free_space
# Call the function with the current directory (you can specify a different path)
total_space, used_space, free_space = disk_space()
print(f"Total space: {readable_format(total_space)}")
print(f"Used space: {readable_format(used_space)}")
print(f"Free space: {readable_format(free_space)}")
|
Total space: 21.47 GB
Used space: 10.34 GB
Free space: 10.50 GB
Clear your browser cache.
Purge your pip cache.
Before purging the Python pip package manager's cache, you can use the pip cache info command to see how much
storage is consumed by the cache.
pip3.11 cache info
Next, use the pip cache purge command
to clear up space on your system. Pip will print how many files it removed to the terminal.
pip3.11 cache purge

Uninstall unnecessary Python libraries.
I tend to build up modules that I installed to see how it works or to quickly test something out,
then never use again. It makes sense to cull your pip installed libraries occasionally.
Be aware that sometimes an unknown module may be a required dependency of a module
you want to use. First, use the pip list command to see your installed libraries:
pip3.11 list
The pip uninstall command makes removing Python libraries easy.
For example, let's say you're already using both the ruff Python linter and black.
The ruff module recently introduced a new formatter that is more or less identical
to Black. Therefore, I can uninstall black and the use "ruff format" command instead
to format my code.
pip3.11 uninstall black
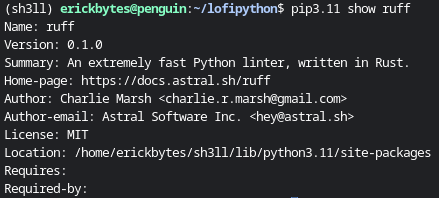
If you're not sure about a package, use the pip show command to learn more about it:
pip3.11 show ruff
Run the autoremove Linux command.
autoremove is used to remove packages that were automatically installed to satisfy
dependencies for other packages and are now no longer needed as dependencies changed
or the package(s) needing them were removed in the meantime.
- Linux apt Man Pages
sudo apt autoremove
Run the clean and autoclean Linux commands.
sudo apt clean
sudo apt autoclean
Read more on Ask Ubuntu: What is the difference between the options "autoclean" "autoremove" and "clean"?
Purge unnecessary Linux packages.
First, create a text file with all your installed Linux packages. Then browse the
packages and assess if they can be safely removed.
apt list --installed > installed_packages.txt
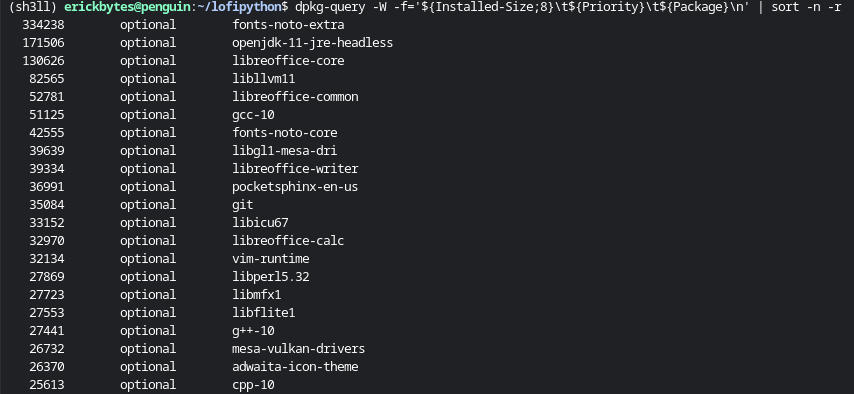
You'll free up more space by deleting the largest optional packages. To list your installed
packages in order of their file sizes and priority, you can use dpkg-query:
dpkg-query -W -f='${Installed-Size;8}\t${Priority}\t${Package}\n' | sort -n -r
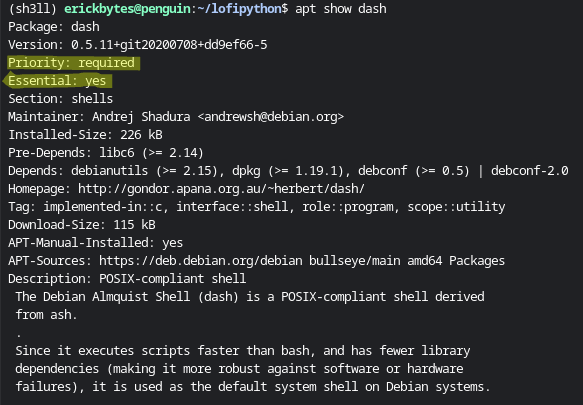
Once you've targeted a package, learn more about it with the apt show command.
It shows if a package is essential or required, a description and its dependency modules.
Optional packages are probably safe to delete assuming it's not a dependency of
software you're actually using. However, purge with caution. Some of these packages are
used in the software underneath your Ubuntu environment. Any leftover packages will
be removed by the autoremove command if they are "orphaned" after you purge a package.
apt show <package-name>
If you are certain a Linux package can be deleted, the apt-get purge command removes
a package and all configuration files from your computer. Be careful not to remove
any critical Linux packages.
sudo apt-get purge <package-name>
Find and delete your largest Linux files.
This command prints the largest files on your root Linux file system. Then you can
use the rm command to remove the file. Hint: sometimes PDF files can be deceptively
large and can be good targets to free up space.
sudo find / -xdev -type f -size +25M -exec du -sh {} ';' | sort -rh | head -n 20
rm ~/large_file.pdf
That sums up a few ways Ubuntu users and Python developers can add some extra available
disk space. It can definitely be frustrating to watch an install fail because there's
no more space on your computer. These are a few strategies you can deploy to make room
to operate on a disk space constrained system.
Feb 05, 2024
Below is a slightly modified adaptation of the Espere.in Step By Step Guide
by Abdulla Fajal. I needed to make a few changes to the code to get things to work.
I also expanded the example to show how I imported cities data to the Django model.
In this post, I'll show how you can use AJAX and jQuery Autocomplete
with a Django model to create a form with city auto-completion.
Add a Model to models.py
| class City(models.Model):
city_name = models.CharField("Origen", max_length=200)
country = models.CharField("País", max_length=200)
|
Register the City Model in admin.py
| from django.contrib import admin
from .models import City
admin.site.register(City)
|
Migrate the Django Model
python manage.py makemigrations City
python manage.py migrate
Add Auto-complete TextInput() to forms.py
The key items here are the "id" attribute holding the value "search-input" and
the "name" attribute with value "city_name". Together, these values will tell jQuery
for which form element to render the autocomplete view and which model field you targeting
to fill into the autocomplete view.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | from django import forms
from bookings.models import Booking
class BookingForm(forms.ModelForm):
class Meta:
model = Booking
fields = "__all__"
widgets = {
"city": forms.TextInput(
attrs={
"class": "form-control",
"id": "search-input",
"name": "city_name",
"placeholder": "Type to search",
}
)
}
|
Download the World Cities Database from Simplemaps
The World Cities Database basic version
is free and allowed for commercial use. In this example, this provides the cities data.
Import the Cities Database to Django Model
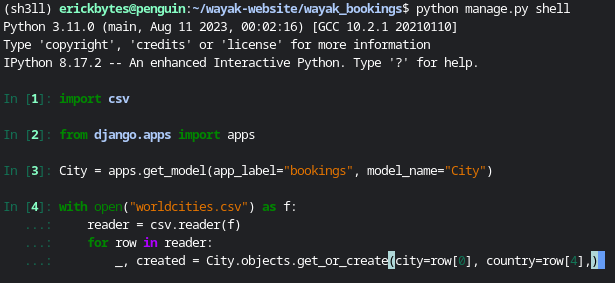
Now we need to import the cities to our Django model. I achieved this by running
the below code in the Django shell and entering each line individually. The code was
modified from a Stack Overflow post.
The World Cities data stores the city in the first column (index 0) and the country
in the 5th column (index 4).
python manage.py shell
| import csv
from django.apps import apps
City = apps.get_model(app_label="bookings", model_name="City")
with open("worldcities.csv") as f:
reader = csv.reader(f)
for row in reader:
_, created = City.objects.get_or_create(city=row[0], country=row[4],)
|
View Your City Model in the Admin Panel
Enter the below command to start your local Django development server. Then you
can go to http://127.0.0.1:8000/admin in a web browser to see your model on the back-end.
python manage.py runserver
Add jQuery Scripts to HTML File
Add the jquery import scripts to your HTML <head> tag.
| <link rel="stylesheet" href="https://code.jquery.com/ui/1.12.1/themes/base/jquery-ui.css" type="text/css" media="all" />
<!-- Add jQuery and jQuery UI JavaScript -->
<script src="https://code.jquery.com/jquery-3.6.4.min.js"></script>
<script src="https://code.jquery.com/ui/1.12.1/jquery-ui.js"></script>
|
Add the jQuery autocomplete script to the bottom of your HTML. This is where we
reference the "search-input" id in our form and specify the url route "/ajax_calls/search/".
1
2
3
4
5
6
7
8
9
10
11
12
13 | <script>
$(document).ready(function(){
$("#search-input").autocomplete({
source: "/ajax_calls/search/",
minLength: 2,
open: function(){
setTimeout(function () {
$('.ui-autocomplete').css('z-index', 99);
}, 0);
}
});
});
</script>
|
Add the Autocomplete View to Views.py
Note this script is using the XMLHttpRequest API,
which is used in combination with AJAX.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37 | import json
from django.apps import apps
from django.forms.models import model_to_dict
from django.shortcuts import render
from forms import BookingForm
from django.http import HttpResponse, HttpResponseRedirect
def index(request):
"""Displays an HTML page with a form. If the request is a post, save the data to the DB."""
if request.method == "POST":
# Create a form instance and populate it with data from the request.
form = BookingForm(request.POST)
if form.is_valid():
new_booking = form.save()
return HttpResponseRedirect(f"/confirmation_page")
context = {}
context["form"] = BookingForm()
return render(request, "simple_django_form.html", context)
def autocomplete(request):
"""Show the City model records via AJAX + jQuery."""
if request.headers.get("x-requested-with") == "XMLHttpRequest":
City = apps.get_model(app_label="bookings", model_name="City")
term = request.GET["term"]
search_results = City.objects.filter(city_name__startswith=term)
cities = [f"{result.city_name}, {result.country}" for result in search_results]
data = json.dumps(cities)
else:
data = "fail"
return HttpResponse(data, "application/json")
def confirmation_page(request):
"""Show a confirmation page thanking the client for their business."""
return HttpResponse("Thanks for signing up!")
|
Write the HTML for a Simple Django Form
Here is the template I used. It differs slightly from the template in the Django docs.
| {% extends 'base.html' %}
{% block content %}
<form method="post">
{% csrf_token %}
{{ form.as_p }}
<input type="submit" value="Submit">
</form>
{% endblock %}
|
Understanding Ajax + XMLHttpRequest
Ajax is a technique that uses XMLHttpRequest to exchange data with a web server
without reloading the whole page. XMLHttpRequest is an object that allows web apps
to make HTTP requests and receive the responses programmatically using JavaScript.
Ajax stands for Asynchronous JavaScript and XML, which means that the data exchange
can happen in the background, while the user interacts with the web page.
- Bing AI
Add the URL Route to urls.py
| from django.urls import path
from . import views
app_name = "your_app_name"
urlpatterns = [
path("", views.index, name="index"),
path("confirmation_page/", views.confirmation_page, name="confirmation page"),
path('ajax_calls/search/', views.autocomplete, name='city_autocomplete'),
]
|
Voila! The City Autocomplete View
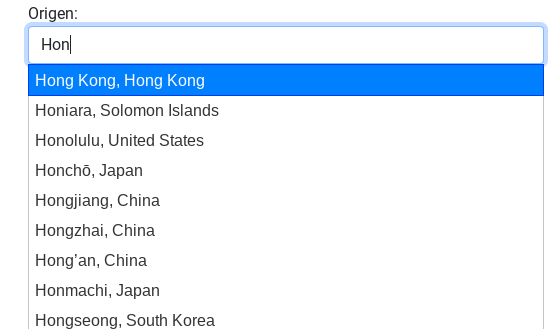
Note: to achieve the appearance of the form text box and autocomplete dropdown, I installed
the django-bootstrap-v5 python module
This felt very rewarding to see once it was working. I stretched my abilities
outside of coding only in Python to achieve this functionality in my website.
Someday I would like to be an experienced Javascript developer also. jQuery has
been a staple in web development for many years. Auto-complete is just one of the features
that this core Javascript library enables. I am definitely intrigued to explore jQuery further.
Want to read more about Django? Check out my
notes on Django here.
Feb 02, 2024
First Impressions of Django
Picking up Django felt right. In the past I used
other Python web frameworks like web2py and flask.
I mostly avoided Django before now because it felt a bit overkill for the smaller
toy apps I made in my beginning years as a Python developer. For example, this blog
is made with the Pelican static site generator, a
choice which has served me well.
Recently, a project came my way that seemed a good fit to apply Django. The task
required building a travel booking website. For this use case, Django shined. It
fits like a glove on a seasoned Python programmer. I am impressed how quickly I
adapted to it and thrived as I made my minimum viable product website.
Kudos to the Django developers that I, a typical Python programmer
aided with artificial intelligence could rapidly develop using their tools to
achieve my goals. If I could learn to write some decent CSS, I'd be unstoppable!
I highly recommend all Python programmers pick Django for their web apps with more
robust requirements. I say this with no slight to fellow heavyweight Flask or other
popular Python web frameworks like Tornado,
Bottle, CherryPy
or py4web . All of these can all be justified in the
right situation due to their unique capabilities. Django stands out because it's
pretty easy to reach for things that already exist in the library to get what you
need done. Other frameworks may require a more nuanced skillset to achieve the same results.
Ok, enough pontification. Here are my notes of key Django concepts.
Start with the Django official tutorial.
The tutorial is lengthy and starts from the ground up. I commend its thoroughness.
Start there and work your way out. Django Documentation Tutorial
Django Models, Forms & Fields, models.py and forms.py
Your forms.py and models.py files are crucial pieces to render a form, collect data
and store it in the database.
manage.py
This file is used for database model migrations, creating a new app and accessing
your app through the shell.
views.py
The views.py file contains the Python functions that execute the flow of your app.
Each function in the views.py can be a view.
urls.py
The urls.py defines your url schema so that when you go to "example.com/any_page",
you can tell django which view to show there.
| from django.urls import path
from . import views
app_name = "bookings"
urlpatterns = [
path("", views.index, name="index"),
path("hotels/", views.hotels, name="hotels"),
]
|
settings.py
After you create your app structure with a django manage.py command, a settings.py is automatically generated.
You will need to make edits here occasionally, such as changing the value of debug
to true or false. You may need to add newly installed apps or make other changes
in your settings.py to get things to work.
HTML + CSS Required
Your HTML and CSS skills will come in handy when working with Django or any web framework.
This is not a big surprise. You almost always need to know HTML and CSS to mold
your website to your requirements.
Django Template Language + Filters
Django comes with its own HTML template language
to help you dynamically populate values in HTML. You can also use its built-in template tags and filters
to transform values directly in the HTML. Additionally, Django lets you write
custom template tags and filters
to use Python for more complex transformations or on the fly mathematic calculations.
Below is an example of how you can use Django's templating language to loop through
your Django model. Django has built-in support for if statements inside its HTML.
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | {% for hotel in hotels %}
<p>
{% if hotel.all_inclusive %}
This hotel is all included.
{% else %}
This hotel is not all included.
{% endif %}
<br>
{% if hotel.accepts_groups %}
This hotel accepts groups.
{% else %}
This hotel doesn't accept groups.
{% endif %}
</p>
|
Javascript + jQuery Friendly
Django seems fully capable of integrating with Javascript libraries. I was able
to get jQuery + AJAX request autocomplete functionality working in my form with
help from Bing's AI Chat. I followed along with this helpful blog post
to get my jQuery script working!
External Django Python Libraries
Another plus of Django due to its popularity is the amount of external modules that
Python developers have written to add features and functionality. For example,
django-autocomplete-light
and the django-bootstrap-v5
CSS library are installed with pip. I successfully used django-bootstrap-v5 to add
bootstrap CSS styling to my website. Note this library requires a slightly older
version of Django.
Often there are several ways to get something done in Django, with external Python libraries
or Javascript libraries each a possibility to succeed. After several hours of
failing to get django-autocomplete-light working, I achieved the same result with
jQuery. It's always good to have options.
The Admin Panel + admin.py
One of the best out of the box features of Django is its admin panel and user model.
If you intend to build a website with for your users, this makes Django a great choice.
Don't forget to register your models in your admin.py.
apps.get_model()
You can import your models at the top of your code or use this handy convenience function to
retrieve it directly.
model_to_dict()
This is another function Django provides for converting a model object class to a Python dictionary.
Once a model is in dictionary format, you can pass it to a django form's "initial" argument
to easily auto-populate a form.
request.GET()
Django has its own request objects. You can pass a raw query string to HttpResponseRedirect.
Then, in the view of the target page, you can use this function to get the querystring
value by passing its key.
render() and contexts
The render function renders an HTML document. This function has a context argument
that allows you to pass variables into the HTML view.
How to Install Django
pip install Django
Django Views.py Code Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 | from django.apps import apps
from django.forms.models import model_to_dict
from django.shortcuts import render
from forms import BookingForm
def index(request):
"""Displays an HTML page with a form. If the request is a post, save the data
to the DB. If booking_id is passed in the url querystring, populate the form
with data from that id."""
if request.method == "POST":
# Create a form instance and populate it with data from the request.
form = BookingForm(request.POST)
if form.is_valid():
new_booking = form.save()
return HttpResponseRedirect(f"/hotels?booking_id={new_booking.id}")
try:
booking_id = request.GET["booking_id"]
except:
booking_id = ""
if booking_id.isdigit():
Booking = apps.get_model(app_label="your_app_name", model_name="Booking")
booking = Booking.objects.get(id=booking_id)
booking_dict = model_to_dict(booking)
context = {}
if booking_dict:
context["form"] = BookingForm(initial=booking_dict)
else:
context["form"] = BookingForm()
return render(request, "simple_django_form.html", context)
def hotels(request):
"""Render a list of hotels to for clients to view from the Hotel model."""
booking_id = request.GET["booking_id"]
Booking = apps.get_model(app_label="your_app_name", model_name="Booking")
booking = Booking.objects.get(id=booking_id)
Hotel = apps.get_model(app_label="your_app_name", model_name="Hotel")
hotels = Hotel.objects.filter(city__contains=booking.to_city)
# Pass context to access variables directly in hotels.html: {{ return_date }}
context = {
"hotels": hotels,
"booking_id": booking_id,
"departure_date": booking.departure_date.date(),
"return_date": booking.return_date.date(),
"to_city": booking.to_city,
}
return render(request, "hotels.html", context)
|
Basic Model Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | from django.db import models
class Booking(models.Model):
departure_date = models.DateTimeField("departure date")
return_date = models.DateTimeField("return date")
from_city = models.CharField("Origen", max_length=200)
to_city = models.CharField("Destino", max_length=200)
class Hotel(models.Model):
name = models.CharField(max_length=200)
price = models.DecimalField(max_digits=10, decimal_places=2)
address = models.CharField(max_length=200)
city = models.CharField(max_length=200)
all_inclusive = models.BooleanField()
photo = models.ImageField(upload_to="hotels")
|
Hopefully this helped you get started with Django. In my own experience, once you
get some momentum going with this web framework, you'll progress rapidly!
Supplementary Django Links
Django Form Fields Reference
Django Model Fields Reference
Django Settings Reference
Django How-to Guides