May 28, 2025
I started writing this blog in 2016. For 5 years, everything I wrote was to learn about new Python libraries
and help other Python programmers learn also. It was an exciting time for me to write and share tech and Python stuff I found
on the internet. In my first years learning Python, I often frantically googled every error message and read Stack Overflow
while working out a new post or building a web app with a new framework. Those days are gone, although I still use Google Search to supplement
my Microsoft Copilot and Google Gemini assistant queries.
In late 2022, OpenAI released ChatGPT. This set off a tidal wave of AI innovation. Nowadays, people are turning less to Google
search and more to AI assistants. This includes the people most likely to read this blog, who I assume are Python developers
or trying to make a thing with Python. As my readers' behaviors change, so do I need to change as a writer.
This brings me to an interesting thought. When I began this blog, I wrote to learn and remember things I've done in the past.
This blog still serves that purpose today. Nonetheless, the way people learn is changing. If I want to
remember how to install Django, now I can use AI to recall it. If I'm having problems with pip, I can paste in the error message
and ask for help fixing it. From 2016-2021, this ability wasn't available. It's a new world now in the ways we consume information and learn.
The tutorial-style writing that used to be common in my blog and others before the AI boom, is now rendered somewhat obsolete.
So what will this blog be going forward? It will still be my technical notes and projects. The difference is it will be more
focused on my own projects, rather than the details of the libraries themselves. I'll try to focus more on how I applied
the libraries to achieve an outcome, rather than rehashing the nuts and bolts of how the libraries I used work.
This is the blog writing pivot that is required in the age of accessible AI assistants. I need to focus more on adding value and experience
to my projects. This is my promise to you, studious reader, for this blog going forward. Instead of pumping out tutorial-style articles
that easily are replaced by an AI chat, I want to go beyond the tutorial to show application. Expect fewer, higher quality Python related
posts with more value added. I hope you enjoy. As always, thanks for reading!
Apr 26, 2025
I saw this default apps post from Trey Hunner
and decided I want to do my own version. Here is my list of apps that I most often use.
| Function |
App/Tool/Service |
|---|
| Domain Registrar |
Namecheap |
| Domain Host (DNS) |
Cloudflare |
| Static Site Generator |
Pelican |
| Music |
Spotify |
| Language Learning |
Duolingo |
| Article Bookmarking |
Pocket |
| Text Editor |
VS Code |
| Email |
Gmail |
| Web Browser |
Chrome |
| RSS Reader |
Feeder |
| Notes |
Google Keep |
| Spreadsheets |
Google Sheets |
| Investment Trades |
Charles Schwab |
| Stock Prices |
Google Finance, Yahoo Finance and Robinhood |
| AI Assistant |
Microsoft Copilot and Google Gemini |
| Messaging |
Whatsapp |
| Cryptocurrency Trading |
Coinbase |
| Translation |
Google Translate |
| Code Versioning |
Github + git |
| Song Discovery |
Shazam |
| Photo Storage and Backup |
Google Photos |
| Document Storage and Backup |
Dropbox |
| Password Manager |
Google Password Manager |
| GPS + Maps |
Google Maps |
| Calendar |
Google Calendar |
| Train |
Amtrak |
| 2 Factor Authentication |
Google Authenticator |
| Sports Scores |
Google Search and Fox Sports |
| VPN |
Turbo VPN |
| QR Code Reader |
QR Reader |
| Ridesharing |
Uber |
| Payments |
Venmo |
| Flights |
Google Flights |
| Accomodations |
Airbnb |
| Guitar Tuning |
Guitar Tuna |
Mar 30, 2025
It has been interesting to see how Python evolved over the past 10 years.
Trends have come and gone. Millions of libraries minted.
What's hot in Python seems to often mirror big technology trends. For example,
with recent advancements in AI, controlling AI models via Python is now common.
Amazon's Boto3 is one of the most downloaded libraries for cloud computing in Python.
Where tech wants to go, Python's popular culture tends to follow.
In any given year, there might not be new foundational libraries introduced.
Or maybe they do get introduced, but it takes time for them to go mainstream.
Here are some popular Python libraries and the year they were introduced:
- FastAPI: 2018
- uv: 2023
- ruff: 2023
- Django: 2005
- Flask: 2010
- pandas: 2008
- requests: 2011
- Google's Gemini AI model
Anecdotally from murmurs online, FastAPI seems to be picking up steam in 2025.
It was introduced back in 2018. This is a great example of how it is extremely rare for a library
to burst out of nowhere and immediately shake up the status quo.
It takes a library a long time to reach critical mass in popularity and to attain
legendary status library like heavyweights numpy, pandas, Django and FastAPI have.
These libraries are well respected by Pythonistas and for good reason. They provide much needed
functionality in an intuitive Python interface.
There should only be one obvious way to do it. Yet, it doesn't stop Python developers from
repeatedly reinventing solved problems. However, sometimes they do improve upon the existing
incumbents in a space. Requests is the obvious example when the urllib HTTP library was already
in the standard library.
While lots of future Python staple libraries could be launching this year,
it is rare for one to make a splash seemingly immediately as black did in 2018 and ruff did in 2023.
In conclusion, the state of Python is healthy in 2025. Every year, new libraries continually rise
to the top of Pythonistas' minds. Advancements in technology are moving forward and so follows
this programming language. But it's not just the cutting edge where we see improvements. The needs
of developers are the same as 10 years ago. We need to build apps and websites. We need to automate
data transfer between systems. We need to make HTTP requests to APIs. Integrate Rust to speed up the Python code.
We need to make things. We need to save time. Fortunately, Python is usually there to help us do it all. With advancements
in AI, we don't need to write the code anymore. What matters is the idea and the execution.
Enough About Now. Predictions for the Future?
New library trends will continue to follow tech advancements:
- The ongoing AI trend. Useful libraries will extend or connect to APIs or LLM models in novel ways or connect to services previously unable to access AI.
- Autonomous driving. Advances in controlling your car autonomously via Python.
- Robotics. Controlling robotic hardware via Python will become more available.
- Python will get faster. With every new release, Python's performance is improved. This trend will continue.
- Businesses that are lucky enough to tap into AI-fueled profits will thrive. They'll employ Python developers to maintain models.
Feb 20, 2025
Being a programmer is not just about learning new libraries and skills.
Some would say that identifying oneself as a "programmer" is foolish.
What we really are is problem solvers. We apply technology or logic to achieve a desired result.
This post details an interesting problem I encountered and how I reasoned to fix it.
I use Google Authenticator as my two factor authorization app. For many websites I use,
this is a layer of security to verify it is actually me signing in.
I started using the app and went years with no problems. Recently, I encountered an issue signing
into my 401K provider's website to check on my 401k. I logged in with my username and password,
then went to the authenticator app when prompted for a code.
But this time, after trying multiple times, I received the error "code invalid".
After so many failed attempts, most websites will lock you out of your account.
This ended up happening to me.
Frustrated, I called the provider's customer support. Eventually, I regained access to my account.
"There's something bonked with my Authenticator app! The codes aren't working.", I told them.
They had no solutions, since the app is from Google and they are a financial services company.
I moved on from the debacle. A month or so later on a different website, this time
a cryptocurrency exchange, I attempted to log in. Once again, the codes were invalid.
I tried multiple times, but seeing it wouldn't work I stopped before a lock was placed on my account.
Since I was dealing with a Google product, I consulted Google's Gemini AI model to seek guidance.
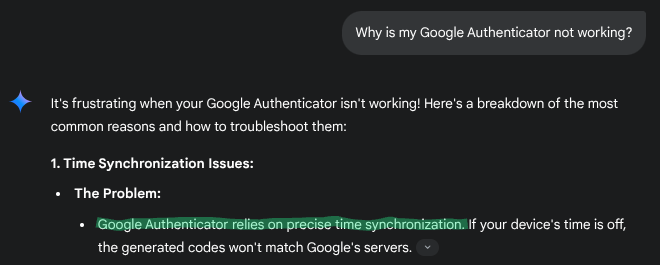
The solution to my problem was just as Gemini suggested: "Google Authenticator relies on precise time precision."
Although the specific solution Gemini offered was not correct, it sent me searching in the right direction.
Gemini told me there was a "time sync setting" in the Authenticator app that didn't exist. Gemini did mention that my phone
should be on "network time".
Bingo. I had manually been setting my time zone due to traveling. I opened up the time settings on my Android cellular phone.
Then I enabled my automatic time settings:
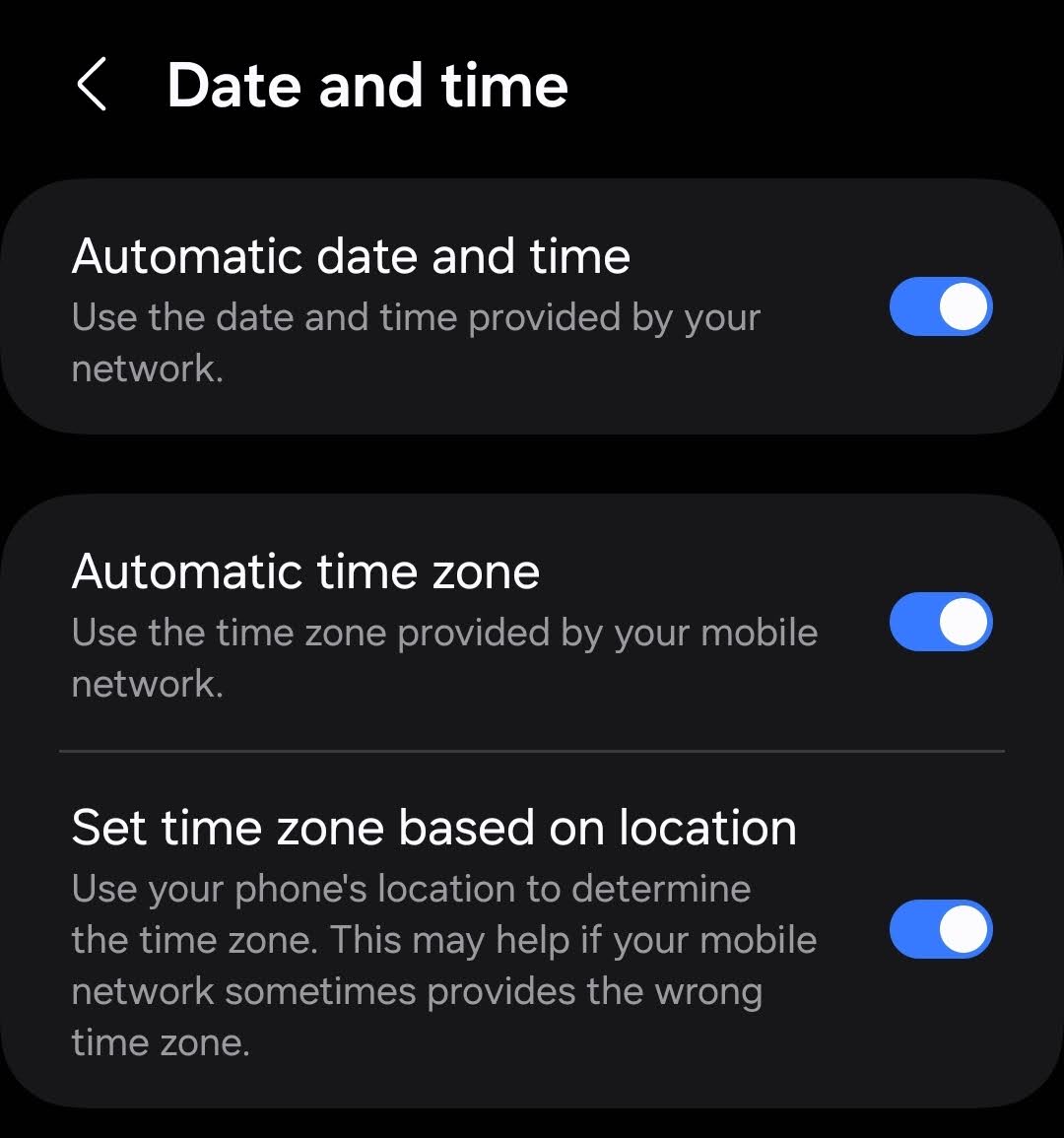
Success! My phone's time settings caused Google Authenticator to display the wrong codes. I logged into my account,
making a mental note that my cell phone clock's settings can indeed cause my two factor authentication app to stop working.
Jan 14, 2025
Recently I had a Google Sheet bogged down so much, Google prompted me to fix it from consuming too many resources in my browser.
So, I pondered how to speed up my Google Sheet and made a short list of ideas. I included some ideas from a great article from
Google about Optimizing Google Sheets.
Strategies for Reducing Load Time in a Google Sheet
Delete all extra columns and rows. Empty rows and columns make the file larger and need to be loaded everytime a Google sheet is accessed. Highlighting and pressing ctrl+D to delete them means they won't be loaded.
Change calculation settings to refresh on a change or "every hour" instead of "every minute". This setting affects functions like NOW(), TODAY() and RAND() are recalculated. Select File > Settings and click the "Calculation" tab to adjust your settings.
Remove expensive, unnecessary, or old unused functions. Each function you use adds additional load to the Google Sheet. By removing extra functions and charts, it will speed up your Sheet and consume less compute resources. This is unique to each Sheet. Think to yourself, is this part of the document necessary? Is it giving value, or can it be cut?
Reduce the number of tabs. Consolidating or removing extra tabs is another way to speed up your load time.
Reference data on the same Sheet when possible.
Reference your data on the same spreadsheet you work on. This is faster than Import functions, such as: IMPORTRANGE, IMPORTDATA, IMPORTXML, IMPORTHTML
Source: Google, Optimize your data references to improve Sheets performance
Use closed range instead of open range references.
An open range spreadsheet means the range starts and ends without indicating a specific row or column. Example: A:B means the range that includes all cells in columns A and B.
A closed range reference refers to the range that starts and ends with a specific row or column.
Example:
A1:B6, A1:C100
Open range: A:B
Closed range: A1:B6
Source: Google, Optimize your data references to improve Sheets performance
Avoid long reference chains when possible.
Reference chains slow down your sheets. For example, in the following case, A2 reads A1 data; A3 reads A2 data; and so on. Because the data is chained together, to calculate the value in A10, Google Sheets waits for all the previous values (A1 to A9) to calculate before it returns the value in A10.
Source: Google, Optimize your data references to improve Sheets performance
Conclusion
Google Sheets are typically very fast until you reach a certain threshold of density. After you reach that point, these changes can speed it up quite a bit!
Dec 28, 2024
In the spirit of the NFL regular season concluding and playoffs beginning soon, I wondered what packages
Python had in the NFL stats space. Below, I have compiled my notes below on each of the libraries I found
for the NFL in Python.
After a first pass through, there is no runaway favorite. In Python, we say "there should be one obvious way to do it". This doesn't seem
the case for NFL stats. In a somewhat rare occurrence, the Python community offers a graveyard of abandoned
or incompatible projects with modern Python. Ultimately, this probably stems from the NFL's inability to provide a consistent stats
API or feed over time. This may be one of the few times where the R community has better resources available,
like the nfldata package in their ecosystem.
Listed in Order of Most Recently Updated Project
- nfl_data_py (Github)
- nfl_data_py is a Python library for interacting with NFL data sourced from nflfastR, nfldata, dynastyprocess, and Draft Scout.
- Github repo status: active
- Github last updated: 3 months ago
- notable dependencies: requires pandas<2.0,>=1.0
- This package seems to be most recently updated, but it requires an outdated version of pandas. I suppose it is the best option since it is updated within the past 3 months, but I was unable to install it on Python 3.12.
- sportsipy (Github)
- A free sports API written for Python
- Github repo status: "This project is no longer undergoing active development. Please consider opening a pull request for any new features or bug fixes to be reviewed and merged."
- Github repo last updated: 2022
- I was able to get the sportsipy package installed via pip, but upon attempting to use it I saw this message: "The requested page returned a valid response, but no data could be found. Has the season begun, and is the data available on www.sports-reference.com?"
- nflfastpy (Github)
- a port of nflfastR, from the R programming language
- Github repo status: "This repository has been archived by the owner on Nov 18, 2022. It is now read-only."
- Github repo last updated: 2021
- notable dependencies: matplotlib
- This package installed on Python 3.12, but when I tried to import the package, I saw a ValueError from matplotlib. Troubleshooting required.
- nfldb (Github)
- nfldb is a relational database bundled with a Python module to quickly and conveniently query and update the database with data from active games. Data is imported from nflgame, which in turn gets its data from a JSON feed on NFL.com's live GameCenter pages.
- Github repo status: "THIS PROJECT IS UNMAINTAINED."
- Github repo last updated: 2018
- notable dependencies: nflgame package (requires Python 2)
- nflgame (pypi)
- nflgame is an API to retrieve and read NFL Game Center JSON data.
- pypi last updated: 2016
- notable dependencies: nflgame requires Python 2.6+ and does not yet work with Python 3
Conclusion
This is one of the few times where I've been unable to find a Python package that does what I want: extend an API to view NFL stats.
I could try some of these packages with an earlier version of Python 3, but I'd prefer to use something that works with a more current version of Python.
My suggestion to anyone looking for NFL stats via Python is: you may need to roll your own package,
or find something like the SportsRadar API
or SportsData.io API. Another option might be to find an existing dataset like the Dynasty Process data on Github.
Oct 28, 2024
I'm a big fan of attempting to draw inspiration from everyday common occurrences. Today, while riding
in a car I saw a clown street performer and remarked to myself about the "product market fit" they
require to earn a living, or lack thereof.
The street clown is not worried about finding the specific right person for their product.
They are also not distracted by getting their messaging right to find exactly their perfect audience.
Rather, they find their customers in real time by finding high traffic areas. Once there,
they set up at a busy intersection with lots of cars or pedestrians. Then, they seek product
market fit by juggling, cycling and doing what clowns do, entertain. People have no choice but to
wait at the intersection in their cars. The clown has performed a service for society. Humor or entertainment
is gained by their customer. They see the clown and think impulsively, "How funny! I'm feeling generous today."
So, a little money changes hands.
The funny thing is that the clown will make some money because people want to support them.
Just because they are there. They are in the arena, hustling for a living like all the people
scurrying by in their cars. The difference is the people in cars are likely on the way
to or from their job, whereas the clown already clocked in.
So what lessons can we learn from a clown performing in the street? Sometimes, we shouldn't be
overly concerned with exactly who is our customer. Marketing says conventionally that the more
you know about your customer base, the better. However, the street performer clown shows it
is not always a requirement. In the clown's case, the requirement is going to high traffic areas
and broadcasting your special brand of entertainment.
The clown earns a small tip from many different customers in passing. They have an advantage in a sense,
because their diversification of customers is high. They are not overly dependent on any specific members of their audience.
This makes their business more resilient, assuming they're taking home enough to make it worth it.
A street entertainer faces a tough prospect: their customers are all going on their way and don't have
the desire to be entertained. This doesn't stop the street clown. They put on the face paint and funky clothes.
They grab their items to juggle, their unicycle, whatever is needed to support their act.
The clown shows up and performs. We would all be more successful if we approached our work like a street performer.
Get out there and make it happen. Don't focus too much on who is the perfect customer.
Get your product in front of people and see what they think. That's the way of the street clown.
Oct 17, 2024
Recently there has been a lot of noise online about the Wordpress website platform.
This blog is formerly a Wordpress blog, so I am able to share from personal experience how
I moved this blog. I began writing the early years of this blog on the Wordpress free plan,
followed by a few years as a paying customer of Automattic, the corporate entity associated with Wordpress.org.
The notes below are from my experience moving to a Python Pelican blog.
Here is the checklist I wrote down when I made than transition:
- Export posts to XML.
- Export all media.
- Convert posts to new blog format: Markdown or reStructuredText Format
- Set DNS redirect from old blog to new blog.
- Update old blog with notice of new blog.
- Set posts to private/public and set search engine + "third party" AI training settings.
- Update urls from old domain to new domain.
Install the Pelican, lxml, beautiful soup and feedparser Python libraries.
pip install pelican
pip install BeautifulSoup4
pip install lxml
pip install feedparser
1. Export posts to XML.
Go into the Wordpress settings and export posts. I selected XML format.
2. Export all media.
Wordpress allowed me to choose to export posts or media, so I exported all the images on my blog also.
3. Convert posts to new blog format: Markdown or reStructuredText Format.
Pelican's import tool for wordpress converts your XML file to either .md or .rst files
based on which CLI argument you pass.
Use the pelican-importer CLI to convert the XML to Markdown or reStructuredText.
I chose to use the default detting of the CLI to export to .rst. If you want to specify a folder to drop the contents,
use the -o argument. Use the -m argument to specify which output format.
| # Convert XML to reStructuredText Format files with default settings.
pelican-import --wpfile example.wordpress.2023-05-14.000.xml
# Convert XML to Markdown files and specify the output directory and format.
pelican-import --wpfile example.wordpress.2023-05-14.000.xml -o ~/projects/example.com/content/blog -m MARKDOWN
|
pelican-importer documentation
4. Set DNS redirect from old blog to new blog.
I previously hosted my blog on a custom .com domain. When I stopped paying for the domain,
my domain reverted back to example.wordpress.com. However, you can pay a domain register a small
fee to forward traffic to your new domain. You can transfer old domain to services like Namecheap
or Cloudflare to set up a redirect. It's recommended to keep a redirect for at least 1 or 2 years
after moving to a new domain to catch any evergreen backlinked traffic.
5. Update old blog with notice of new blog.
Keep A Few Posts Exclusively on the Old Blog
The benefit of Worpdress's free plan is that you can still keep some posts
and the original sub-domain live on their free plan.
Write your final post on the old blog to let subscribers know you've moved.
I had built up a list of subscribing Wordpress users after 6 years writing on the platform.
Write a brief post explaining where to find future blog posts to let your audience know where to find you.
In my case, I wrote a goodbye post on my old blog,
and an announcement post about on my new blog domain.
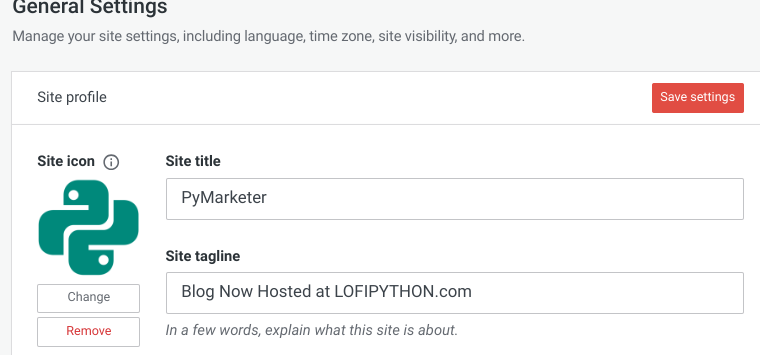
Update the Site Tagline on Your Old Blog
I also set the old blog's tagline to point readers to new blog. In Wordpress Settings / General,
you can edit the site tagline:

6. Set posts to private/public and set search engine + "third party" AI training settings.
Once I got the hang of Pelican, I reviewed each converted post to fix links, grammar or formatting errors
from the conversion. I slowly moved my converted posts over in batches of 2 or 3 posts at a time.
As I moved the posts to the new blog, I chose to set the old posts individually to private within the Wordpress
editing CMS, rather than at the sitewide level. By setting posts to private, they're also still accessible to
your Wordpress subscribers by direct url link. Setting individual posts to private allows subscribers who are
following legacy links to have a chance to find my new home on the web. For non-subscribers, the private links
will break, however they will still see an error page on your old blog. From there, they might see the site
tagline directing to the new blog or find a few of the posts I reserved exclusively for the legacy blog.
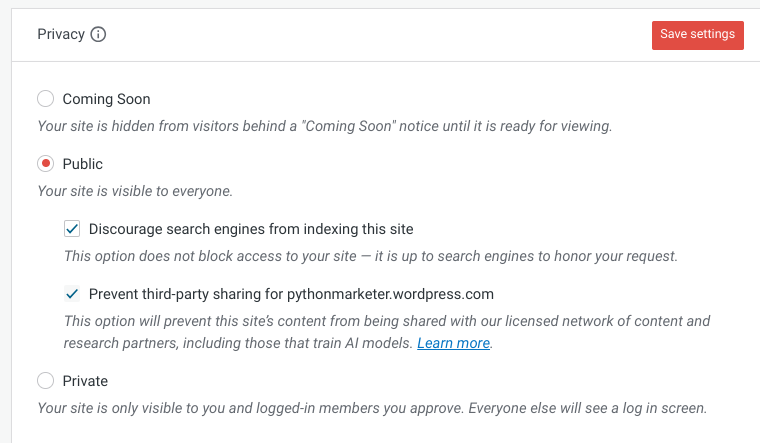
One benefit of Wordpress from an SEO perspective is that they have search engine indexing control
in the settings panel. In the settings, you have the ability to tell search engines whether or
not you should index your blog. I set my old Wordpress site settings to "Discourage search engines
from indexing this site" and "Prevent third-party sharing for example.wordpress.com". The third party
sharing setting prevents Wordpress from using your posts to train their AI models.
7. Update urls from old domain to new domain.
It's common practice to add a "CTA" or call to action at the end of a blog post.
For me, that tends to be the related posts I've written in the past.
Any links that contain the old domain need to be swapped to the new one.
For validating urls in my 100+ past posts, I also wrote a python script to help find broken links and .rst tags here:
rst-url-validator Github Repo
Moving From Wordpress Was Easy With Pelican
I did thorough research into Python static site generators
before choosing Pelican. The benefits of Pelican include a Wordpress import CLI that makes it easy to quickly
compile an an alternative MVP to move your blog from Wordpress. Pelican is an obvious choice for static site
generation in the Python ecosystem. After 17 months of using it, I can safely say I'm happy with the decision!
Supplementary Reading
Deploy a Hugo website to Cloudflare
How to Convert a Wordpress blog to an Astro Static Site
Pelican Documentation
Launching a Live Static Site Blog via Pelican, Github and Cloudflare Pages
Sep 25, 2024
I began paying attention to what was relevant in the tech scene around 2014, in my 20s.
Back then, I was just getting started studying Python. It was an interesting time in tech.
The term "Big Data" was getting tossed around a lot, but the pandas library hadn't yet reached mass adoption
in data circles like it now has today. People were still talking about Hadoop + Map Reduce. (RIP)
In the 2010s, it didn't take much perusing online to find people in the Python community bashing Microsoft.
If tech companies were a high school, Apple was the cool kid everybody wanted to know, Microsoft was the
kid who nobody liked and everyone made fun of. Understandably, the Windows operating system didn't mesh
with Python programming as well as Linux or Mac OS. By 2024, Microsoft gained their mojo back, or found the mojo
they never had. Having used Windows a lot at my last job, I recognize the OS and its Python implementation have flaws.
I still got my work done and had no problems, without complaining. I continued to play around on Windows and write Python
on it even though people trashed it online. I'm glad I did!
How did Microsoft flip Apple? Steve Ballmer left the company in 2014, yielding to Satya Nadella as CEO.
Since then, the company culture shifted miraculously. In the Python community, they have made a huge impact
by investing in the language. They constantly release free Python + AI courses, and integrated Excel with Python.
Guido, the creator of Python is employed full-time, working on improving the Python language. That tells you a lot
of how much has changed since Python's BDFL is still working there after 3 years. Microsoft's culture change propelled it into
the 2020s with newfound momentum. With some timely bets, they saw the AI revolution coming and capitalized first.
If someone feels this way in 2024, they probably don't want to admit: Microsoft is Apple in 2012,
and Apple is Microsoft in 2012.
What is funny to see is that nowadays, fewer people are bashing Microsoft. I used to see it regularly,
people teeing off online, "writing Python on Windows is such a terrible experience for XYZ thing, why is Windows so awful??""
I see less of those people posting such thoughts now. Maybe they're still out there. If someone feels this way in 2024,
they probably don't want to admit: Microsoft is Apple in 2012, and Apple is Microsoft in 2012. I posit they
switched places in respective coolness among tech circles. People realized Apple is not the friend of developers
or society in general. They are self-serving to a vicious degree. Apple is focused on maintaining their walled garden on iOS.
Microsoft is now a better advocate for techies and Python development. Sure, some people prefer to code on Macs,
more power to them. Linux is typically the favorite of the three and it is awesome. It's also not released by a
for profit corporation which is uber cool to developers.
Apple is also less cool due to their battle with Epic Games and insistence on 30% rake for in-app
purchases on iOS. Not to mention an unwillingness to change their policies to appease stricter European Union regulations
for things like 3rd party app stores.
Microsoft is integrating AI deep into their products. Apple, after being slow on the uptake to AI,
followed Microsoft's lead to invest in OpenAI and roll its AI chat to iPhones.
Who is the leader here? In terms of "What have you done for me lately?", it's Microsoft. In terms of who supports open
and free information, it's Microsoft. Who's cool now?
Sep 07, 2024
Bots and robots.txt
Bots are crawling the internet. They make up a large chunk of all web traffic.
On my blogs, I've always used a robots.txt
to say to bots, "scrape away!" like this:
User-agent: *
Disallow:
Some websites use a robots.txt to say, "don't scrape our content".
We can ask crawlers to restrict from crawling, but this is more or less an honor system.
For this blog, I always welcomed all real traffic but activated Cloudflare's "Bot Fight Mode" to
to protect against some of the bots.
Cloudflare Rolls Out New AI Blocker Configuration
I noticed in my Cloudflare Pages dashboard that a new setting has become available to me on the free plan.
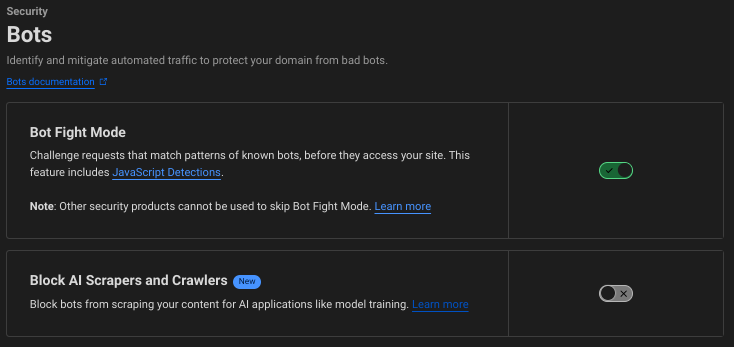 Block AI Bots Cloudflare Pages Configuration
Block AI Bots Cloudflare Pages ConfigurationThis new configuration option gives another level of security if I want to use it.
For now, I'm choosing to keep my blogs open to most traffic, including AIs while excluding some bots.
Anyone who publishes to the internet needs to assess their willingness to trust big tech's bots to scrape their data.
You can block artificial intelligence (AI) bots, crawlers, and scrapers from scraping
your website content and training large language models (LLM) to recreate it without
your permission. When you enable this feature via a pre-configured managed rule,
Cloudflare can detect and block AI bots from your website.
- AI Bots
If an LLM is just a remix of all the data it consumes, how do we trace the origin of its results?
And how does that get attributed back? It seemed easier to tell with Google's link based search results.
But even then, there was a lack of transparency. It's still that way today. I appreciate that Cloudflare is putting
this choice to block or not block AIs in the hands of website makers. They're also releasing
an "AI Audit" tool that lets website owners set a price for their sites with AI crawlers.
This murkiness leaves site owners with a hard decision to make.
The value exchange is unclear. And site owners are at a disadvantage while they play catch up.
Many sites allowed these AI crawlers to scan their content because these crawlers,
for the most part, looked like "good" bots - only for the result to mean less traffic
to their site as their content is repackaged in AI-written answers
...
We think that sites of any size should be fairly compensated for the use of their content.
Cloudflare plans to launch a new component of our dashboard that goes beyond just blocking
and analyzing crawls. Site owners will have the ability to set a price for their site,
or sections of their site, and to then charge model providers based on their scans
and the price you have set.
- Start auditing and controlling the AI models accessing your content, Cloudflare Blog
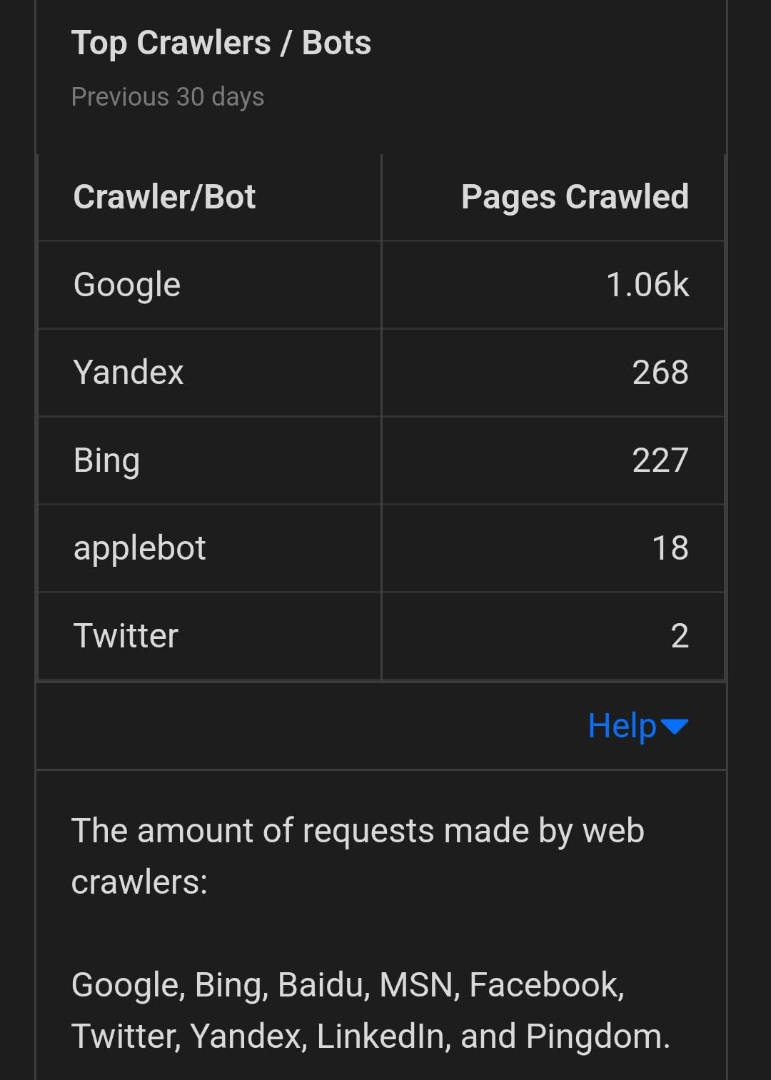 Crawler Traffic on lofipython.com, Aug. - Sept. 2024
Crawler Traffic on lofipython.com, Aug. - Sept. 2024The point of this post is to reflect on the nuances of web creators and their relationship with big tech.
Everyone will have to decide for themselves if they think it's worth it. In this case, we're likely "paid in exposure".
Big tech will distill the value of what we write to inquiring humans and reference back with links. Will website creators
lose out on this exchange? Are we cutting off a channel of distribution if we push back against LLMs scooping up our data?
Right now there seems to be more questions than answers. We'll see.
Disclosure: the author is a Cloudflare investor, going on 3 years holding shares.