Should You Block LLMs and Bots From Your Website?
Bots and robots.txt
Bots are crawling the internet. They make up a large chunk of all web traffic. On my blogs, I've always used a robots.txt to say to bots, "scrape away!" like this:
User-agent: * Disallow:
Some websites use a robots.txt to say, "don't scrape our content". We can ask crawlers to restrict from crawling, but this is more or less an honor system. For this blog, I always welcomed all real traffic but activated Cloudflare's "Bot Fight Mode" to to protect against some of the bots.
Cloudflare Rolls Out New AI Blocker Configuration
I noticed in my Cloudflare Pages dashboard that a new setting has become available to me on the free plan.
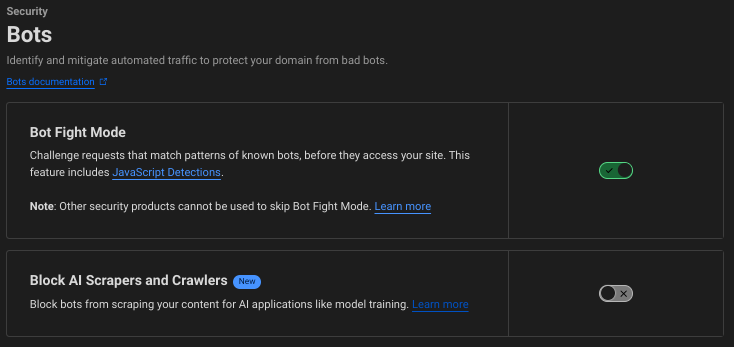
This new configuration option gives another level of security if I want to use it. For now, I'm choosing to keep my blogs open to most traffic, including AIs while excluding some bots. Anyone who publishes to the internet needs to assess their willingness to trust big tech's bots to scrape their data.
You can block artificial intelligence (AI) bots, crawlers, and scrapers from scraping your website content and training large language models (LLM) to recreate it without your permission. When you enable this feature via a pre-configured managed rule, Cloudflare can detect and block AI bots from your website.
- AI Bots
If an LLM is just a remix of all the data it consumes, how do we trace the origin of its results? And how does that get attributed back? It seemed easier to tell with Google's link based search results. But even then, there was a lack of transparency. It's still that way today. I appreciate that Cloudflare is putting this choice to block or not block AIs in the hands of website makers. They're also releasing an "AI Audit" tool that lets website owners set a price for their sites with AI crawlers.
This murkiness leaves site owners with a hard decision to make. The value exchange is unclear. And site owners are at a disadvantage while they play catch up. Many sites allowed these AI crawlers to scan their content because these crawlers, for the most part, looked like "good" bots - only for the result to mean less traffic to their site as their content is repackaged in AI-written answers
...
We think that sites of any size should be fairly compensated for the use of their content. Cloudflare plans to launch a new component of our dashboard that goes beyond just blocking and analyzing crawls. Site owners will have the ability to set a price for their site, or sections of their site, and to then charge model providers based on their scans and the price you have set.
- Start auditing and controlling the AI models accessing your content, Cloudflare Blog
The point of this post is to reflect on the nuances of web creators and their relationship with big tech. Everyone will have to decide for themselves if they think it's worth it. In this case, we're likely "paid in exposure". Big tech will distill the value of what we write to inquiring humans and reference back with links. Will website creators lose out on this exchange? Are we cutting off a channel of distribution if we push back against LLMs scooping up our data? Right now there seems to be more questions than answers. We'll see.
Disclosure: the author is a Cloudflare investor, going on 3 years holding shares.